Based on the overview of private clouds in my prior blog, here’s the 5-step recipe for launching your implementation:
- Identify the list of applications that you want to deploy on the cloud;
- Document and publish precise end-user requirements and service levels to set the right expectations – for example, time in hours to deliver a new database server;
- Identify underlying hardware and software components – both new and legacy – that will make up the cloud infrastructure;
- Select the underlying cloud management layer for enabling existing processes, and connecting to existing tools and reporting dashboards;
- Decide if you wish to tie in access to public clouds for cloud bursting, cloud covering or simply, backup/archival purposes.
Identify the list of applications that you want to deploy on the cloud
The primary reason for building a private cloud is control – not only in terms of owning and maintaining proprietary data within a corporate firewall (mitigating any ownership, compliance or security concerns), but also deciding what application and database assets to enable within the cloud infrastructure. Public clouds typically give you the option of an x86 server running either Windows or Linux. On the database front, it’s usually either Oracle or SQL Server (or the somewhat inconsequent MySQL). But what if your core applications are built to use DB2 UDB, Sybase or Informix? What if you rely on older versions of Oracle or SQL Server? What if your internal standards are built around AIX, Solaris or HP/UX system(s)? What if your applications need specific platform builds? Having a private cloud gives you full control over all of these areas.
The criteria for selecting applications and databases to reside on the cloud should be governed by a single criterion – popularity; i.e., which applications are likely to proliferate the most in the next 2 years, across development, test and production . List down your top 5 or 10 applications and their infrastructure – regardless of operating system and database type(s) and version(s).
Document precise requirements and SLAs for your cloud
My prior blog entry talked about broad requirements (such as self-service capabilities, real-time management and asset reuse), but break those down into detailed requirements that your private cloud needs to meet. Share those with your architecture / ops engineering peers, as well as target users (application teams, developer/QA leads, etc.) and gather input. For instance, a current cloud deployment that I’m working with is working to meet the following manifesto, arrived at after a series of meticulous workshops attended by both IT stakeholders and cloud users:
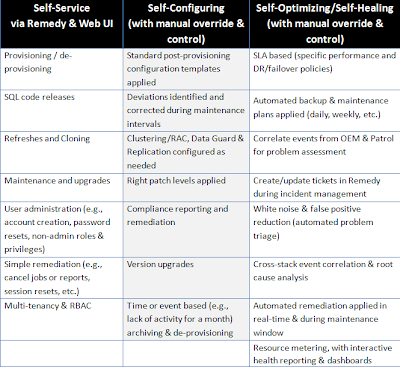
In the above example, BMC Remedy was chosen as the front-end for driving self-service requests largely because the users were already familiar with using that application for incident and change management. In its place, you can utilize any other ticketing system (e.g., HP/Peregrine or EMC Infra) to present a friendly service catalog to end users. Up-and-coming vendor Service-now extends the notion of a service catalog to include a full-blown shopping cart and corresponding billing. Also, depending on which cloud management software you utilize, you may have additional (built-in) options for presenting a custom front-end to your users – whether they are IT-savvy developers, junior admin personnel located off-shore or actual application end-users.
Identify underlying cloud components
Once you have your list of applications and corresponding requirements laid out, you can begin to start the process of defining which hardware and software components you are going to use. For instance, can you standardize on the x86 platform for servers with VMware as the virtualization layer? Or do you have a significant investment in IBM AIX, HP or Sun hardware? Each platform tends to have its own virtualization layer (e.g., AIX LPARs, Solaris Containers, etc.), all of which can be utilized within the cloud. Similarly, for the storage layer, can you get away with just one vendor offering – say, NetApp filers, or do you need to accommodate multiple storage options such as EMC and Hitachi? Again, the powerful thing about private clouds is – you get to choose! During a recent cloud deployment, the customer required us to utilize EMC SANs for production application deployments, and NetApp for development and QA.
Also, based on application use profiles and corresponding availability and performance SLAs, you may need to include clustering or facilities for standby databases (e.g., Oracle Data Guard or SQL log shipping) and/or replication (e.g., GoldenGate, Sybase Replication Server).
Now as you read this, you are probably saying to yourself – “Hey wait a minute… I thought this was supposed to be a recipe for a ‘simple cloud’. By the time I have identified all the requirements, applications and underlying components (especially with my huge legacy footprint), the cloud will become anything but simple! It may take years and gobs of money to implement anything remotely close to this…” Did I read your mind accurately? Alright, let’s address this question below.
Select the right cloud management layer
Based on all the above items, the scope of the cloud and underlying implementation logistics can become rather daunting – making the notion of a “simple cloud” seem unachievable. However here’s where cloud management layers comes to the rescue. A good cloud management layer keeps things simple via three basic functions:
- Abstraction;
- Integration; and
- Out-of-the-box automation content
Data Palette does not post restrictions on server, operating system and infrastructure components within the cloud. Its database Solution Packs support various flavors and versions of Oracle, SQL Server, DB2, Sybase and Informix running on UNIX (Solaris, HP/UX and AIX), Linux and Windows. Storage components such as NetApp are managed via the Zephyr API (ZAPI) and OnTapi interfaces.
However in addition to out-of-the-box integration and automation capabilities, the primary reason for keeping complexity at bay is due to the use of an abstraction layer. Data Palette uses a metadata repository that is populated via native auto-discovery (or via integration to pre-deployed CMDBs and monitoring tools) to gather a set of configuration and performance metadata that identifies the current state of the infrastructure, along with centrally defined administrative policies. This central metadata repository makes it possible for the right automated procedures to be executed on the right kind of infrastructure – avoiding mistakes (typically associated with static workflows from classic run book automation products)) such as executing an Oracle9i specific data refresh method on a recently upgraded Oracle10g database – without the cloud administrator or user having to track and reconcile such infrastructural changes and manually adjust/tweak the automation workflows. Such metadata-driven automation keeps the automation workflows dynamic, allowing the automation to scale seamlessly to hundreds or thousands of heterogeneous servers, databases and applications.
Metadata collections can also be extended to specific (custom) application configurations and behavior. Data Palette allows Rule Sets to be applied to incoming collections to identify and respond to maintenance events and service level violations in real-time making the cloud autonomic (in terms of self-configuring and self-healing attributes), with detailed resource metering and administrative dashboards.
Data Palette’s abstraction capabilities also extends to the user interface wherein specific groups of cloud administrators and users are maintained via multi-tenancy (called Organizations), Smart Groups™ (dynamic groupings of assets and resources), and role based access control.
Optionally tie in access to public clouds for Cloud Bursting, Cloud Covering or backup/archival purposes
Now that you are familiar with the majority of the ingredients for a private cloud rollout, the last item worth considering is whether to extend the cloud management layer’s set of integrations to tie into a public cloud provider – such as GoGrid, Flexiscale or Amazon EC2. Based on specific application profiles, you may be able to use a public cloud for Cloud Bursting (i.e., selectively leveraging a public cloud during peak usage) and/or Cloud Covering (i.e., automating failover to a public cloud). If you are not comfortable with the notion of a full service public cloud, you can consider a public sub-cloud (for specific application silos e.g., “storage only”) such as Nirvanix or EMC Atmos for storing backups in semi-online mode (disk space offered by many of the vendors in this space is relatively cheap – typically 20 cents per GB per month). Most public cloud providers offer an extensive API set that the internal cloud management layer can easily tap into (e.g., check out wiki.gogrid.com). In fact, depending on your internal cloud ingredients, you can take the notion of Cloud Covering to the next level and swap applications running on the internal cloud to the external cloud and back (kind of an inter-cloud VMotion operation, for those of you who are familiar with VMware’s handy VMotion feature). All it takes is an active account (with a credit card) with one of these providers to ensure that your internal cloud has a pre-set path for dynamic growth when required – a nice insurance policy to have for any production application – assuming the application’s infrastructure and security requirements are compatible with that public cloud.
